
Most people confound an APU to be the same as an Integrated GPU (iGPU) and today we’re going to make mince meat of that phantasm, unveiling the enigmatic truth behind an APU. This article will highlight and eloquently describe everything that you might want to add to your journal for understanding APUs.
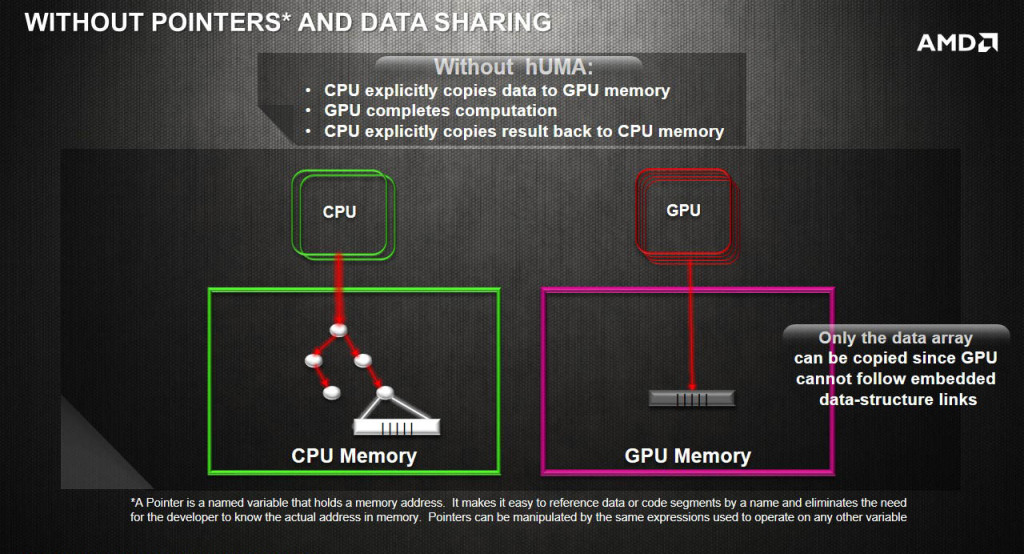
For aeons, it has been proven by GPUs that they are unparalleled at handling tasks that require parallelism such as Matrix multiplication and addition. But recent times have revealed that it isn’t always the GPUs that will suffice in solving these problems. Often, it is required that the GPU and CPU work in a tandem and hence, currently data has to be copied between the GPU and CPU frequently which induces, well you guessed it ; additional overhead.
Most applications today will copy data from the RAM to the GPU memory over the PCIe bus which is relatively slow in comparison to the computation pace of both the GPU or the CPU. In case where the results from the computation of the GPU have to be consistently read by the CPU, the data copy becomes strenuous and induces overhead which can potentially stall the pipeline of either the GPU or the CPU.
Now, there arise two reasons why faster data transfer becomes necessary :-
- Discrete GPUs today come with a hefty amount of VRAM and often to hide the latency between the context thread switching, the entire frame buffer is saturated with compute and graphics threads.
- Both the GPU and CPU have distinct address spaces and neither can understand the information of the other’s address spaces. iGPUs (The ones found on intel CPUs) share the same physical memory but still do not possess the machinery to make sense of each other’s virtual address spaces.
Hardware manufacturers for years tried to introduce technologies that could attenuate the amount of overhead but virtually no steps were taken to erase it from its very existence. AMD and HSA foundation came up with a solution and today, while APUs might be one of the ignored sections of the PC industry, it is critical to understand the significance that they could possibly build in the near future with HSA 2.0 and Bristol / Stoney Ridge APUs on the cards.
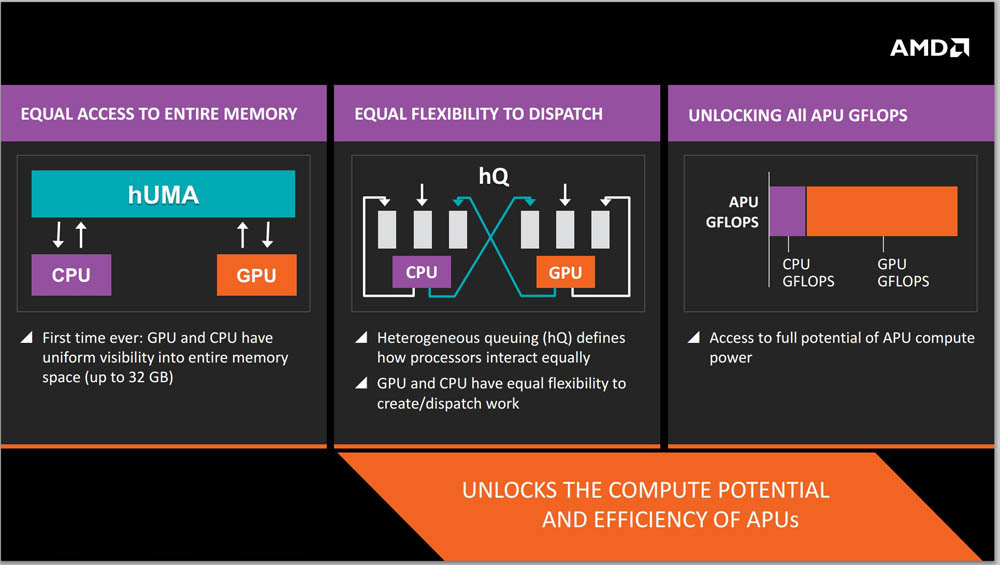
- Unified Memory : The term Unified or Shared memory is often bemused and swaps places with the latter but at its core, the difference is a noteworthy one. While shared memory only means that the GPU and CPU both utilize a shared pool of memory ; unified memory’s real strength lies in the fact that both the GPU and the CPU are well acquainted with each other’s virtual address spaces and do not need a third party to assist in making sense of it. And with that misconception out-of-the-way, lets jump into the complexities of HSA and comprehend the major advantages that they tout over traditional iGPUs and dGPUs.
hUMA (Heterogeneous Unified Memory Architecture)
APUs are held together by the structure of hUMA and now, we’ll go through the capabilities of Unified memory that are offered by HSA, visiting each and every benefit that the Memory architecture sports.
- Elimination of CPU-GPU data copies : The GPU now has the capability to access the CPU’s entire address space without requesting a data copy. This significantly reduces overhead.
- Access to CPU’s address space : hUMA not only eliminates data copies but also brings along an efficacious improvement over the traditional frame buffer of the GPU. Discrete GPUs are retailed with onboard RAM and the ones out in the market currently top out at 12 GB in contrast to which the CPU has had access to much larger pools of memory. Access to the entire address space of the CPU ensures the GPU the same capacity of the system memory. This allows the GPU to work on much larger amounts of datasets without drawing in more and more of it in a data fetch and waiting for the second pool of data thereafter. With the latest generation of APUs on the AM4 platform, this would mean that the APU would now have access to much faster and a much larger pool of memory which would qualify as a huge advantage.

- Unified Addressing : No other system currently offers this profit. HSA is the first to implement it. Application programs allocate memory in a virtual CPU address space and the OS is yielded with the responsibility to maintain a mapping between the virtual and physical address spaces. When a load instruction is encountered, the CPU converts these virtual addresses into physical ones with assistance from the OS. The GPU too has its own virtual address space and previously had no idea of the CPU’s address space. With HSA, the GPU can peep into the CPU’s book and allocate a GPU page table without requesting a data fetch from the CPU, thereby eliminating a significant cause of overhead. With this feature, the CPU and GPU can have access to the same address space simultaneously and can operate on the same sets of data in harmony.
- Demand-driven paging : Allocating CPU and GPU addresses is a non-trivial task and generally requires OS intervention. In some cases, the OS may or may not know what range of memory addresses it has to map to a GPU buffer object. The GPU driver then locks the concerned pages in memory and proceeds to its computation. Demand driven paging addresses this issue by allowing sharing of arbitrary data structures between the GPU and CPU.
- Optional Cache Coherence : As the readers might have already gathered, the most crucial advantage that HSA and APUs boast of is the elimination of data copies but it is important to realize that the GPU is better at some jobs and the CPU at others. In such cases, unnecessary cache coherence can cause undesirable delay and hence HSA provides for tools through which the programmer can decide whether the provide for the luxury of cache coherence or not. Thereby, ameliorating the flexibility of the system.

Wrapping it up
APUs have remained in the shadows of dGPUs and CPUs for too long and often their significance has been overlooked by PC enthusiasts. But the future of APUs appears stellar with the 7th generation of APUs from AMD very proximal. With access to much faster memory such as HBM in the not so distant future we could expect APUs to lock horns with dGPU offerings from Radeon and nVidia.







