
Asynchronous shaders have been touted as one of the biggest architectural advancements that the GPU industry has witnessed over the last few years. Over the years, all the high level APIs employed linear execution of threads when a disparity in the job was spotted, namely – Graphics, Compute and Data. Last year, Microsoft revealed its latest API, DirectX 12 which zeroed in on its prime highlight – Asynchronous Shading. Ever since then, all the low level APIs to surface such as Vulkan have paid major heed to making Asynchronous Shading a feature that is effortless to tune and easy to implement. But today, I won’t be making ostentatious claims such as Asynchronous Shading (Will be referred to as Async later on) being a game changer ; instead, the crux of today’s argument is whether Async is what it flaunts to be or is it just another gimmick?
To comprehend this, we must first look into the traditional linear execution of GPU threads and then how it stands in contrast to the parallel execution of Graphics and Compute threads. It is crucial to note that while GPU tasks are in themselves embarrassingly parallel, it is quite counter-intuitive to be running Compute and Graphic threads in parallel.

Running a typical DirectX 11 game, the GPU is bombarded by innumerable threads segregated into again – Graphics, Compute and Data. These instructions are fed to the Graphics command processor in succession without being overlapped. The Graphics Command Processor then assigns shader units to the task in consideration. An efficient way which ensures that all the threads are executed in a linear manner but holds a manifest disadvantage, that of pipeline stalling. If in case, a graphic or compute thread occupies the pipeline for a spanning duration, the pipeline effectively gets stalled and this impedes other threads from being executed. Techniques such as pre-emption are utilized in such cases where a priority is drawn between the more important tasks and the lesser ones. This proved to be an effective method of dealing with thread execution but left many holes such as insufficient GPU utilization on some titles.
How are Asynchronous Shaders different?
Asynchronous shaders make use of a trivial technique called ‘Out of order execution’ and as the name implies, the shaders are capable of handling tasks in an asynchronous manner, as the situation calls. There isn’t a stone-studded method about how the GPU must execute the chores that are assigned to it. The graphics command processor and the Asynchronous Compute engines are apparently similar with the only distinction being that the Graphics command processor has access to the entire GPU unlike the ACEs which can access only the compute shaders.

When the ACEs encounter a compute thread, instead of waiting for the Graphic thread to end, they assign compute cores to execute the concerned thread. This assists in reducing latency and in turn increasing the FPS. The key role of the ACEs is to ensure that the GPU is never redundant and is always kept busy regardless of whether the Graphic threads are already saturated or not. The larger the pool of compute threads, more are the options for the ACEs to pick. In an ideal situation, the GPU pipeline would never stall and the utilization would remain dogged at 100%.
Why is AMD better at it?
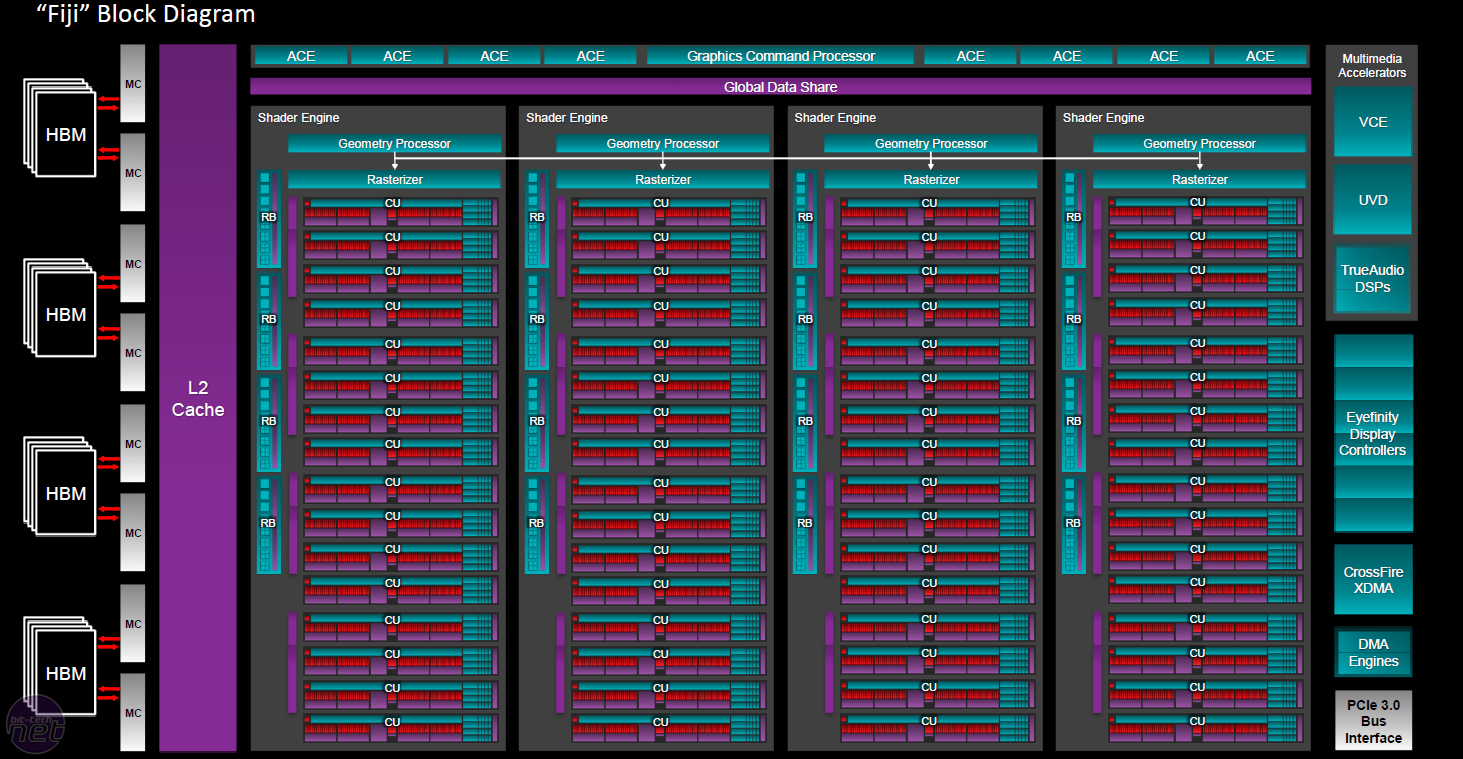
If we examine the block diagram of a Fury X, we can observe that at the apex are situated eight Asynchronous Compute Engines and a graphics command processor. We can calculate the number of Stream processors by multiplying the total number of Compute units by 64. This equates to a total of 4096 Stream processors on an uncut Fiji GPU (R9 Fury X). A common trouble that the Fury X faced while running DX11 titles was that of improper GPU utilization and this is solely because of unorganized GPU clusters, a large number of them. In comparison to the Titan X which only sports 3072 CUDA cores for shader units, the number is significantly enormous on a Fury X which is why it fails to achieve maximum utilization on certain titles.
This issue is accounted for by Asynchronous Shaders. On DX11 titles. It was mainly the compute cores that were left unfed and stalled because of time spanning Graphic threads. With ACEs, the compute cores are never vacant and a marked improvement can easily be noted, especially on a fine tuned title to support Asynchronous Shading such as Ashes of the Singularity. The beta release of the benchmark had its fair share of controversies with nVidia making claims such as MSAA interfering with the GPU performance. It was later found that Maxwell GPUs although comprised of a much larger number of Compute Queues but were lacking on an analog scheduler and had to rely on slow context switching if Async Compute was enabled. This can be better explained through the following benchmarks :-
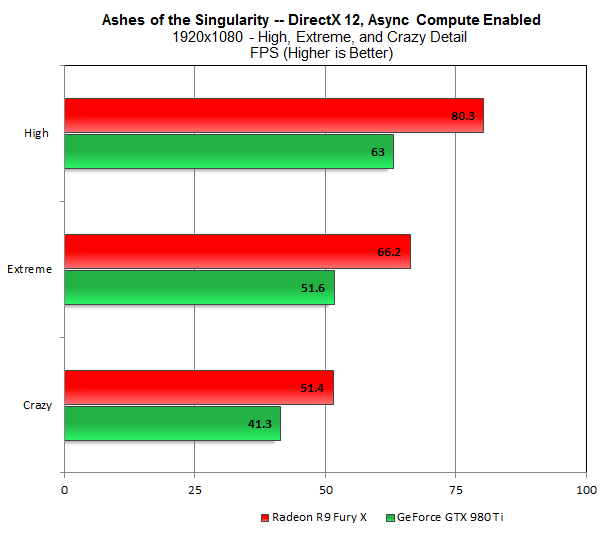
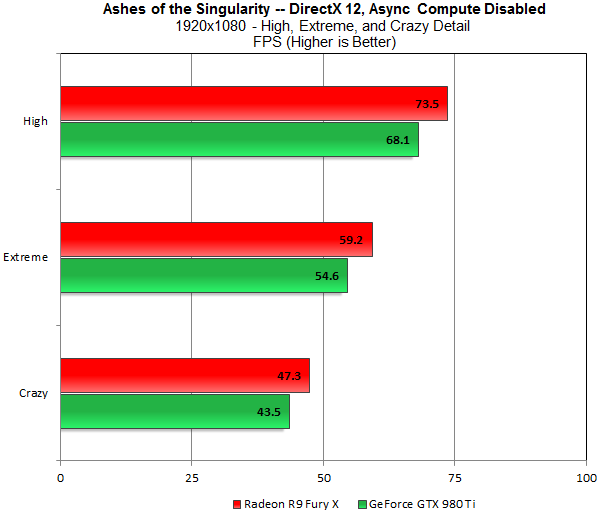 Source : ExtremeTech
Source : ExtremeTech
As can be observed from the benchmarks above that even with Async Compute disabled, the Fury X scores a relatively higher frame rate than the 980 Ti which is quite flummoxing since generally, it’s the other way round; but as soon as Async Compute is enabled, the Fury X witnesses a performance bump of up to 10% whereas the 980 Ti is left in sort of a misery with a reasonable FPS drop.
Now the million dollar question that arises is whether the improvement is because of patent architectural advantages of the Fury X, or whether it solely owes that to Asynchronous shaders proving to be a magnificent asset to GCN GPUs. Let us recall the number of Stream processors on the Fury X and the number of CUDA cores on a Titan X, a mind boggling 4096 Vs 3072, the latter of which were efficiently put to use on the Titan X as far as DX11 titles are concerned. It can be surmised from the numerous DX11 benchmarks that the Maxwell architecture is the more efficient of the two and does not require additional components or software tweaks to sweat the entire structure, but there’s a catch to this. As opposed to nVidia, AMD always chose to increase the Shader core count and didn’t pay enough heed to the fact that over 800 of those cores weren’t being utilized by the GPU, with DX12 and Vulkan in the house, they can count on their handy ACEs to ensure optimal GPU utilization. But what’s the outcome when such an approach is skipped? Well, that can be demonstrated by DX12 titles such as Rise of the Tomb Raider.
The ultimate conclusion
While it appears that it’s only AMD who has benefitted from Asynchronous shaders, we can’t be oblivious of the fact that the only incitement of Asynchronous Shaders is to promote better GPU utilization by operating on more threads in parallel. If nVidia can somehow workout their way into this technology, it can only count as a win-win situation for the consumers since Async isn’t evil. At least in my opinion, it isn’t a gimmick ; it does what it’s supposed to do without flinching. However hard to tune it may be, the truth remains that Asynchronous Shading is a revolutionary technology in the GPU industry. When multithreading was introduced into the CPU industry, it was first discarded as an ‘inefficient’ alternative to Multi-processing but look around today and you’d observe that multithreading is a holy grail for CPUs.
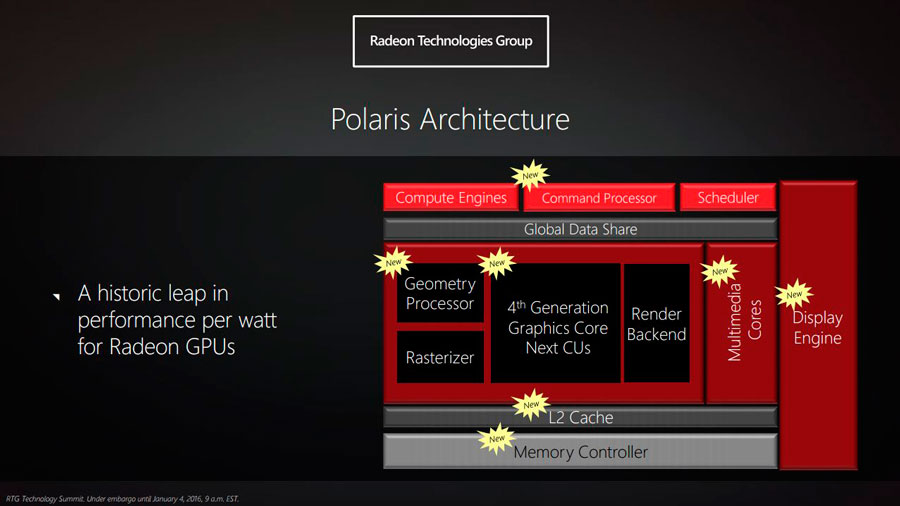
With further advancements, I expect Asynchronous Compute to only ameliorate and rise in ranks before it becomes a mainstream approach to scheduling Graphics and Compute threads. There is no denying the fact that AMD will not only want to preserve their lead in the DX12 market by improving their Async efficiency but also will strive to achieve better architectural efficiency, which is quite evident from the new Polaris architecture already. nVidia however, doesn’t look too intrigued and has already opted for Pre-emption against Asynchronous Shaders in their Pascal lineup but I whole heartedly hope that the Volta GPUs will sport an effective analog scheduler along with ACEs. If this is realized, we could expect a major proportion of the future titles to feature Async Compute considering nVidia’s generation spanning imperialism in the gaming industry.




